
When Three Trust Models Fail at Once
The Claude Chrome Extension and the End of a Comfortable Story About Browser AI

In brief
Two disclosures in six months, ShadowPrompt and ClaudeBleed, hijacked the same Claude Chrome extension by entirely different routes and reached the same outcome. The usual takeaway, that browser AI is risky and vendors are patching, sits at the wrong altitude.
An LLM in the browser cannot tell who an instruction came from. “Summarise this page” looks the same whether the user typed it, another extension forwarded it, or a hidden element on the page planted it. The trust decisions happen in the surrounding software, which is where both attacks failed.
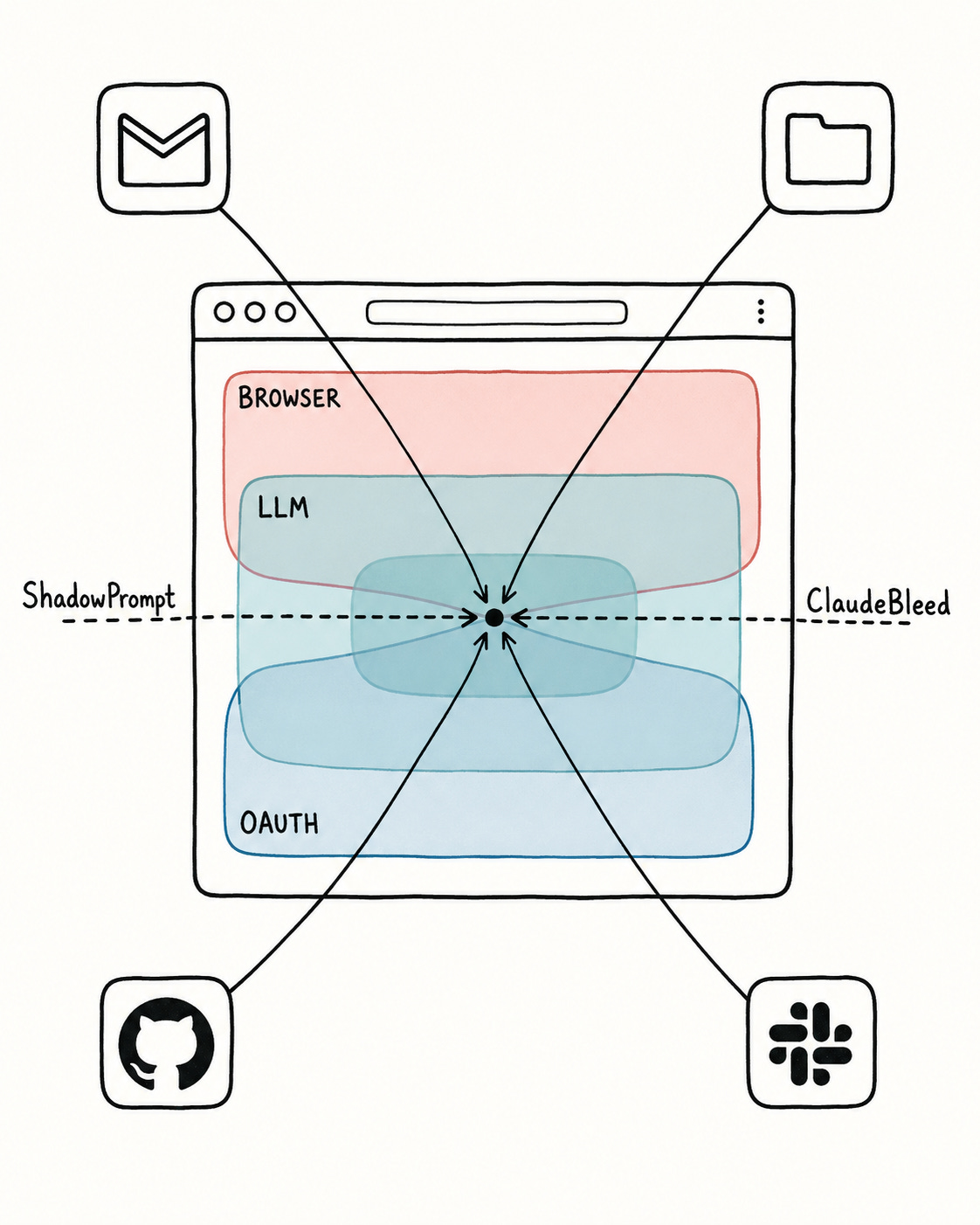
Underneath the patches, three trust models now share one execution context: the browser model (sandbox, origins, permissions), the LLM model (system over user over page content, and only probabilistically), and the SaaS OAuth model (durable tokens for Gmail, Drive, GitHub). A failure in one becomes a failure in all, and the composition is nobody’s responsibility.
Human-in-the-loop confirmation stops holding up. An attacker can forge the approval, or rewrite the dialog so the user and the assistant are looking at different things. The control assumed both see the same UI, which is no longer guaranteed.
The procurement questions change accordingly: what OAuth grants accumulate and where the tokens live, how confirmation is protected from DOM manipulation, and who owns the trust composition when it breaks. The pattern is not Claude-specific; it follows the architecture across browser, desktop, and IDE assistants.
Two disclosures in the last six months involving the same extension, by two different research teams, produced the same outcome through almost entirely different mechanisms. In December 2025, Koi Security reported a zero-click chain it called ShadowPrompt, exploiting a permissive subdomain allowlist combined with a DOM-based cross-site scripting flaw in an Arkose Labs CAPTCHA component hosted on a-cdn.claude.ai. Visiting a webpage was enough. The attacker’s prompt landed in Claude’s sidebar as if the user had typed it. Anthropic shipped an origin-tightening patch in extension version 1.0.41 on 15 January 2026, and Arkose Labs fixed the upstream XSS on 19 February 2026.
Three months later, LayerX disclosed a second vulnerability the firm named ClaudeBleed. This one had nothing to do with subdomain origin checks or XSS. It exploited the extension’s externally_connectable manifest setting, which trusts the origin of incoming messages but does not verify the execution context within that origin. Any other Chrome extension, even one declaring zero special permissions, could inject scripts into the claude.ai page, send messages through that pipe, and pilot Claude as if the user were issuing the commands. LayerX demonstrated extraction of files from Google Drive, transmission of emails on behalf of the user, and theft of source code from a connected GitHub repository. Anthropic patched in version 1.0.70 on 6 May 2026. LayerX reported that switching the extension into a privileged “act without asking” mode bypassed the new checks.
Both stories produced the predictable wave of coverage, and the framing was familiar: browser AI is risky, prompt injection is hard to defend against, vendors are racing to patch, users should update.
That framing is not wrong, but it sits at the wrong altitude. Whether the Claude Chrome extension is uniquely insecure matters less than what the two disclosures, taken together, reveal about the architecture any browser-resident AI assistant has to inhabit, and why the standard list of security recommendations cannot reach the underlying problem. The honest answer is uncomfortable for everyone selling agentic browser tools, including Anthropic, Google, and the dozen smaller vendors building in this space. The architecture itself concentrates three previously independent trust models into one execution context, and once that has happened, no patch on any single layer fully restores the separation the original threat models assumed.
This is worth unpacking carefully, because the conclusion bears on procurement decisions, on board-level questions about agentic AI rollouts, and on how cyber insurance underwriters are likely to start pricing this class of exposure over the next year.
What actually changed when an LLM moved into the browser
For most of the history of enterprise security, the browser was a hostile environment that the security team accepted as a fact of organisational life: users would click on things, pages would try to load scripts from places they should not, and extensions would request permissions they did not need. The discipline built up to handle this was the Chrome extension security model, which rests on three foundations.
The first is sandboxing. Extensions run in a constrained execution environment, separate from the page and from each other, with explicit permission grants required to read tabs, modify requests, or access storage.
The second is origin-based trust. The extension declares which origins it wants to communicate with, the browser enforces those declarations, and origins themselves are treated as the unit of security boundary.
The third is the human in the loop. For sensitive actions like reading clipboard contents, accessing camera or microphone, or modifying network traffic, the user receives an explicit prompt and either approves the action or blocks it.
Each of these foundations developed in response to a specific class of historical attack: sandboxing handles the case where an extension itself is malicious or compromised, origin-based trust handles the case where one page tries to take action on behalf of another, and the human-in-the-loop step handles the case where neither the page nor the extension can be fully trusted to make decisions about consequential operations.
None of those three foundations were designed for the case where the user-facing surface inside the extension is a language model.
A language model behaves nothing like a deterministic UI, with no fixed action vocabulary that can be enumerated and gated. It accepts natural language input, infers intent, and produces actions that may be entirely novel from one session to the next. When the input comes from the user, this is exactly what we want. When the input comes from somewhere else, the model has no native mechanism to distinguish between the two sources. The text saying “summarise this page” looks identical whether the user typed it, an extension forwarded it, or a hidden div on the page contains it as injected content. Decisions about which inputs to trust happen outside the model, in the surrounding software, in the extension’s message-handling code, in the origin checks, in the consent flows.
Both ShadowPrompt and ClaudeBleed are failures of that surrounding software rather than of the model itself, and specifically failures of the assumption that the model, once given an instruction, will reliably defer to meta-instructions about which sources are authoritative.
This matters because once you understand the architecture this way, you see why patching is not a complete answer. Anthropic tightened the origin check after ShadowPrompt and added approval flows after ClaudeBleed. Both fixes close the specific reported attack path without touching the structural condition that the model, by design, sits in a position where it can be reached by any party that finds a route into the message pipeline. The route in version 1.0.41 differed from the route in version 1.0.70, but the class of attack was identical in both cases.
The three trust models that have now merged
The reason this matters in operational terms, and the reason the eventual remediation will be slower and more painful than a vendor patch suggests, is that browser-resident AI assistants do not sit inside a single trust model. They sit at the intersection of three.
The first is the browser trust model, governed by the Chrome extension manifest, content security policies, sandboxing rules, and the permission framework. This is the model that has been tested by twenty years of adversarial pressure. It is well understood, well documented, and reasonably sound when implemented correctly.
The second is the LLM trust model, which is much newer and much less mature. It rests on the model’s ability to follow system prompts in preference to user prompts, to follow user prompts in preference to embedded content, and to ask for confirmation before taking consequential actions. None of these properties are guaranteed, and all of them can be eroded by adversarial input. The defences remain probabilistic rather than absolute. Anthropic’s own documentation for computer use explicitly acknowledges that content on webpages or in images can conflict with user instructions and cause Claude to make mistakes, even with classifier-based defences layered on top.
The third is the SaaS OAuth trust model, which is what gives the assistant the ability to do anything interesting. The user, at some prior point, granted the assistant access to Gmail or Google Drive or GitHub or a corporate Slack workspace. That grant is durable, surviving session boundaries, and it does not require reconfirmation for each individual action. Once the OAuth token exists in the extension’s reach, the assistant has effective custody of the credentials.
Before agentic browser AI, these three models existed in separate parts of the security architecture and were defended by separate teams using separate tools. The browser team worried about extensions and origins, the application security team about prompt injection in chatbots that had no ability to take actions, and the identity team about OAuth scope and consent. The defensive posture was distributed.
What ShadowPrompt and ClaudeBleed demonstrate, with two very different exploitation chains, is that all three trust models now share an execution context. A failure in one is a failure in all of them. An attacker who finds a way to inject prompts (a failure in the LLM trust model) gains access to OAuth tokens (a failure in the identity trust model) through a route that the browser security model was not designed to consider authoritative (a failure in the browser trust model). Each individual model worked as designed; the composition broke.
This is the kind of failure mode that does not show up in a single product’s threat model, because each product is only responsible for one of the trust layers. The LLM vendor does not own the OAuth tokens, the SaaS application vendor does not own the extension’s message handling, and the browser vendor does not own what the LLM does once it receives input. The composition becomes nobody’s responsibility precisely because no single party can fully see it.
Why “user confirmation” stopped being a defence
One of the more interesting details in the LayerX disclosure is the description of how user confirmation was bypassed. Claude, like most contemporary agentic assistants, enforces an additional step before taking sensitive actions. The user is shown what is about to happen and asked to approve. This is the human-in-the-loop control that has been the backstop of browser security since the original Chrome extension permission model was designed.
LayerX showed two ways this control fails in the new architecture. The first is repeated confirmation messages, where the attacker’s script forges the user approval by sending the confirmation message itself, sometimes multiple times to overwhelm any rate limiting. The second is DOM manipulation, where the attacker modifies the visible UI to alter what Claude perceives the user is approving, so the user sees a dialog asking for permission to do one thing while Claude reads a dialog that has been quietly rewritten to ask for permission to do something else.
The implication is sharper than it first appears. The human-in-the-loop control assumes that the human and the assistant are seeing the same UI. In a traditional Chrome extension this assumption was reasonable, because the UI was rendered by the browser and not interpretable by the extension. In an agentic assistant the UI is rendered by the browser, observed by the assistant, and acted on by the assistant. The integrity of the user’s view and the assistant’s view are no longer guaranteed to be the same view. Any party that can write to the DOM can desynchronise them.
The concern is concrete rather than theoretical. The LayerX proof of concept did exactly this, and the user could be looking at a dialog that says one thing while Claude is reading a dialog that says something else.
For practitioners, the lesson is that the standard advice (require explicit confirmation for sensitive actions) needs a stronger formulation. The confirmation must be cryptographically tied to the action, not visually presented, and reconciled between the user’s view and the assistant’s view through a channel the attacker cannot rewrite. None of the current browser AI assistants implement this, and whether the Chrome extension model can support it without significant architectural changes remains an open question.
What this means for the procurement conversation
For directors and senior executives evaluating whether to allow agentic browser AI inside the organisation, the standard checklist of questions misses the most important ones. The standard checklist tends to focus on data residency, model selection, conversation logging, and whether the vendor has SOC 2 attestations. These are appropriate questions, but they are the wrong questions to ask first.
The first questions to ask are these.
What OAuth grants does this assistant accumulate over the course of normal use, and where are those tokens stored? If they are stored in browser local storage, who else can reach them? If they are stored in the extension’s protected storage, what is the verification model for callers that send messages to the extension? In both ShadowPrompt and ClaudeBleed, the failure mode was that the extension’s verification model accepted callers it should not have accepted.
What sensitive actions does the assistant enforce confirmation for, and how is the integrity of that confirmation flow guaranteed against DOM manipulation? If the answer involves visual presentation in the page, the control does not hold up against the class of attacks demonstrated this year.
What is the vendor’s response when a researcher reports a problem outside the immediate exploit but inside the same architectural pattern? Anthropic’s response to LayerX was that the issue was already known and would be fixed in the next version. That is a reasonable response. The follow-up question is whether the next version addresses the broader pattern or only the specific path. In this case the answer was the specific path, which is why LayerX was able to demonstrate a second exploitation route in the privileged mode.
Who owns the trust composition? When the same execution context contains the browser model, the LLM model, and the OAuth model, which party is accountable for the composition? The answer at most organisations today is that nobody is. The CISO covers identity, the application security lead covers application vulnerabilities, and the AI governance owner (if such a role exists) covers model behaviour. Composition risk falls between the seams.
This disclosure fits into a wider pattern
It would be a mistake to read these incidents as Claude-specific. Unit 42 published research in March 2026 on Gemini Live in Chrome that described the same architectural pattern from a different angle, showing how extension-based compromise of an agentic browser assistant could lead to local file access, screenshots, camera and microphone exposure, and broader privacy invasion. Implementation details differ across the products, while the security direction is consistent. Once an assistant is a privileged surface inside the browser with the ability to read content, execute scripts, and take cross-site action, compromise of that surface produces outcomes that previously required full remote code execution.
There is also a parallel development worth noting in the desktop space. LayerX itself published research earlier this year on Claude Desktop Extensions, showing that MCP-based connectors with full system privileges could be triggered by content arriving through low-risk connectors such as Google Calendar. The vulnerability earned a CVSS 10 out of 10, and after the researchers reported it, Anthropic determined that the user had consented to this class of behaviour by enabling the connectors and chose not to fix it.
I am not raising that desktop case to suggest Anthropic is uniquely careless. The desktop case illustrates the same structural pattern from a different angle. When a model has been granted a wide set of permissions across heterogeneous data sources, any data source with a path to the model becomes, in effect, a path to the union of those permissions. The legal frame here is consent; the operational frame is composition.
The pattern repeats because the underlying architecture is the same. Browser, desktop, IDE plugin, code assistant, mobile companion app. Every place that an agentic AI is given hands to act on the user’s behalf becomes a place where the trust composition of multiple previously independent layers becomes the new attack surface.
What an actually useful response looks like
I do not think the answer is to refuse to deploy this category of tooling. The productivity case for assistants that can actually do things in the user’s environment is real, and the organisations that figure out how to use them safely will have a material advantage over those that wait. Waiting for the vendor to solve it is also not the answer, because the vendor will close specific exploit paths and the class of attack will reappear in a different form. This is the historical pattern of every previous extension security disclosure, and there is no reason to expect this one to break that pattern.
What is required is recognition that browser-resident agentic AI is operating in a substrate where three trust models that were previously separate have collapsed into one. This recognition needs to be reflected in procurement, in monitoring, and in incident response.
In procurement, the question has shifted from whether the assistant is useful to what the assistant’s blast radius is when (not if) the trust composition is breached. Useful tools with small blast radii deserve different treatment from useful tools with large blast radii. Most current deployments do not make this distinction, because the trust composition is invisible at the moment of purchase.
In monitoring, the standard endpoint and SaaS audit logs are insufficient. As Mitiga’s parallel research on Claude Code OAuth interception demonstrated, traffic generated by a compromised assistant looks identical to legitimate traffic on the SaaS side. The user, the session, the IP address resolving to the expected egress range, the action looking like exactly the kind of action the user performs routinely: all of it reads as authentic in the audit log. Detection has to happen earlier, in the configuration drift and the message-handling patterns of the assistant itself, rather than in the downstream audit logs.
In incident response, the standard playbook for compromised browser extensions (remove the extension, rotate any exposed credentials, force re-authentication on all connected services) is necessary but insufficient. The connected SaaS services may have been used to establish persistence through other means: created mailbox rules, shared documents, created repository forks, modified webhook endpoints. The incident does not end when the extension is removed.
None of this is comfortable, and none of it is what most organisations are currently equipped to do. The disclosures from Koi and LayerX are early markers, not the end of the conversation about browser AI security: markers that the comfortable story we have been telling ourselves about how this category of tooling fits into existing security frameworks is no longer adequate.
The frameworks themselves will have to change, since the trust composition already has. The vulnerabilities will keep arriving until both have caught up.
Sources and references
Ionut Arghire. “Vulnerability in Claude Extension for Chrome Exposes AI Agent to Takeover.” SecurityWeek, 8 May 2026. https://www.securityweek.com/vulnerability-in-claude-extension-for-chrome-exposes-ai-agent-to-takeover/
Aviad Gispan. “ClaudeBleed: How a Zero-Permission Chrome Extension Can Hijack Claude.” LayerX Security blog, 5 May 2026. https://layerxsecurity.com/
Derek B. Johnson. “Flaw in Claude’s Chrome extension allowed ‘any’ other plugin to hijack victims’ AI.” CyberScoop, 8 May 2026. https://cyberscoop.com/claude-chrome-extension-allows-plugins-to-hijack-ai/
Shweta Sharma. “Claude in Chrome is taking orders from the wrong extensions.” CSO Online, 9 May 2026. https://www.csoonline.com/article/4168867/claude-in-chrome-is-taking-orders-from-the-wrong-extensions.html
Oren Yomtov. “ShadowPrompt: How Any Website Could Have Hijacked Claude’s Chrome Extension.” Koi Security blog, 26 March 2026. https://www.koi.ai/blog/shadowprompt-how-any-website-could-have-hijacked-anthropic-claude-chrome-extension
The Hacker News. “Claude Extension Flaw Enabled Zero-Click XSS Prompt Injection via Any Website.” 26 March 2026. https://thehackernews.com/2026/03/claude-extension-flaw-enabled-zero.html
SOCRadar. “ShadowPrompt: Zero-Click Prompt Injection Chain in Anthropic’s Claude Chrome Extension.” 27 March 2026. https://socradar.io/blog/shadowprompt-zero-click-anthropics-claude/
Penligent. “Claude Extension Prompt Injection — How ShadowPrompt Turned a Trusted Subdomain Into a Browser-Scale Risk.” 28 March 2026. https://www.penligent.ai/hackinglabs/claude-extension-prompt-injection-how-shadowprompt-turned-a-trusted-subdomain-into-a-browser-scale-risk/
LayerX Security. “Claude Desktop Extensions Exposes Over 10,000 Users to Remote Code Execution Vulnerability.” 12 February 2026. https://layerxsecurity.com/blog/claude-desktop-extensions-rce/
SQ Magazine. “ClaudeBleed Bug Lets Chrome Extensions Hijack Claude AI.” 8 May 2026. https://sqmagazine.co.uk/claudebleed-chrome-extension-hijack-claude-ai/
Anthropic. Computer Use documentation, public guidance acknowledging conflicts between webpage content and user instructions in agentic contexts. https://docs.claude.com
Palo Alto Networks Unit 42. Research on agentic browser assistants and Gemini Live in Chrome, March 2026.